3 min read.
Todo lo que necesitas saber sobre Amazon EC2
Las organizaciones de hoy en día buscan soluciones innovadoras, confiables y efectivas de...


El monitoreo de infraestructura de la nube es sumamente importante y AWS— dentro del marco del Well Architected lo toma muy en cuenta. En este artículo presentamos CloudWatch, que es la herramienta por excelencia para el cumplimiento de este cometido y que en iNBest.cloud te ayudamos de principio a fin para conseguir un perfecto funcionamiento.
CloudWatch es una herramienta que AWS nos ofrece para la obtención y recopilación de datos de toda nuestra infraestructura en la nube, nos ayuda a monitorear el comportamiento de nuestros aplicativos pero además, nuestra infraestructura on-premise. Con CloudWatch podemos obtener una vista unificada de nuestros recursos, detectar comportamientos anómalos y tomar acción de manera automática.
iNBest.Metrics
Basada en los cinco pilares del Well Architected Framework1 ; iNBest.Metrics nace como una plataforma todo en uno, y por medio de la cual los usuarios de la nube se mantienen dentro de las mejores prácticas de manera constante, buscando de manera integral la seguridad de las cargas, su correcto performance y la reducción de costos.
 1 AWS Well Architected Framework: Excelencia operativa, seguridad, fiabilidad, eficacia en el rendimiento y optimización de costos.
1 AWS Well Architected Framework: Excelencia operativa, seguridad, fiabilidad, eficacia en el rendimiento y optimización de costos.
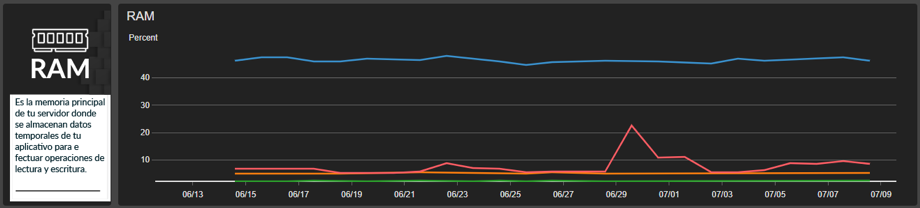
El monitoreo continuo y unificado de todo el funcionamiento de tu infraestructura de tu nube, es una pieza fundamental para el cumplimento de las mejores prácticas dictadas por AWS, iNBest.Metrics soluciona este dilema de manera sencilla y práctica para los usuarios, recopila datos de monitorización y operaciones en formato de registros, métricas y eventos, y permite su visualización mediante paneles automatizados para obtener una vista unificada de los recursos.
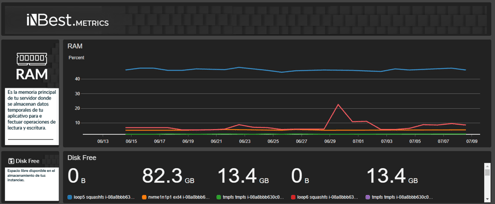
Además de métricas personalizadas y añadidas a la capa básica de monitoreo, resultando en un seguimiento mucho más robusto y completo.
Por medio de la visualización, podemos concluir variedad de conjeturas en busca de optimizar nuestros recursos, además que observar el comportamiento del uso de CPU a través del tiempo, nos ayuda a entender cómo nuestro aplicativo funciona en la nube.
Sin embargo, varias veces no es suficiente data, entonces la mejor práctica es entender nuestra carga con diferentes enfoques. Uno de ellos y que iNBest.Metrics lo incluye es el apartado de RAM, que es información valiosa y determinante al momento de realizar un downgrade de tamaño de instancia.
A continuación, en este artículo describiremos las métricas específicas y cómo estas nos ayudan a vigilar nuestros recursos de manera integral.
Ejemplo práctico:
Imaginemos una carga de trabajo que tenga uso de CPU promedio en un mes por debajo del 10%. Con esta información podría ser sensato realizar un downgrade de nuestra instancia para pagar menos y ahorrarnos algunos dólares al mes:
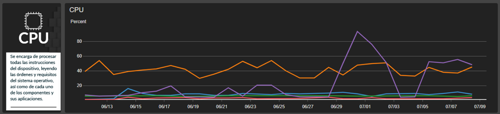
Este es solo un ejemplo de cómo las visualizaciones que nos aporta iNBest.Metrics nos ayudan a tomar mejores decisiones, pero hay más valor aún, a continuación, se muestran las descripciones por métrica que nos otorga el dashboard.
Toda esta información se secciona por instancia o disco y como concluimos, es información extremadamente relevante al momento de monitorear nuestras cargas de trabajo, asegurar su correcto funcionamiento y siempre buscar la optimización de costos dentro de nuestra nube.

Continúa leyendo artículos relacionados en nuestro blog:


