5 min read.
Business Intelligence con AWS
Actualmente, vivimos en la era de la información donde todo tipo de acciones, procesos, entidades,...


Data lake te permite almacenar toda tu información estructurada y no estructurada de manera centralizada.
Además es posible ejecutar diferentes tipos de análisis de datos como consultas SQL, análisis de big data, búsqueda de texto completo, análisis en tiempo real y aprendizaje automático para toma de decisiones.
¿Para qué sirve un Data Lake?
Permite identificar y actuar ante oportunidades de crecimiento para los negocios más rápido gracias a que permite:
Diferencias entre Data Lake y Data warehouse
Un Data warehouse es una base de datos optimizada para analizar datos relacionales provenientes de sistemas transaccionales y aplicaciones de líneas de negocio. La estructura de los datos y esquema están definidos para incrementar la rapidez de bases SQL.
Lo que se traduce en mejor análisis y operaciones.
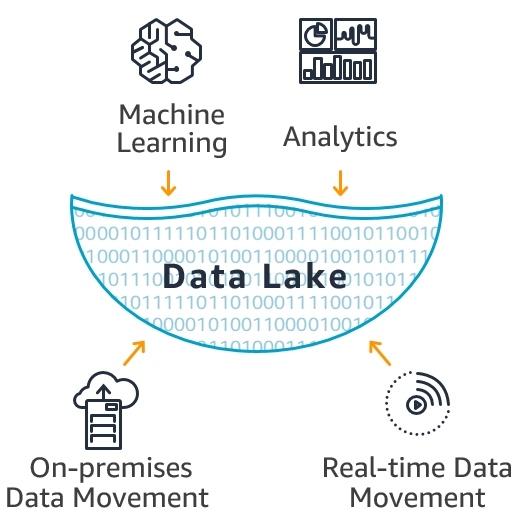
Un Data Lake es diferente, ya que almacena datos relacionales de aplicaciones de negocio y datos no relacionales de aplicaciones moviles, dispositivos IoT y social media. Su estructura no está aún definida cuando los datos son capturados, esto significa que es innecesario tener definido un diseño o preguntas que sean posibles de responder con la información.
Actualmente las empresas están migrando de Data warehouse a Data lake ya que ofrece la habilitación de diversos algortimos, uso de data science y nuevos modelos de información.
|
Characteristics |
Data Warehouse |
Data Lake |
|
Data |
Relational from transactional systems, operational databases, and line of business applications |
Non-relational and relational from IoT devices, web sites, mobile apps, social media, and corporate applications |
|
Schema |
Designed prior to the DW implementation (schema-on-write) |
Written at the time of analysis (schema-on-read) |
|
Price/Performance |
Fastest query results using higher cost storage |
Query results getting faster using low-cost storage |
|
Data Quality |
Highly curated data that serves as the central version of the truth |
Any data that may or may not be curated (ie. raw data) |
|
Users |
Business analysts |
Data scientists, Data developers, and Business analysts (using curated data) |
|
Analytics |
Batch reporting, BI and visualizations |
Machine Learning, Predictive analytics, data discovery and profiling |
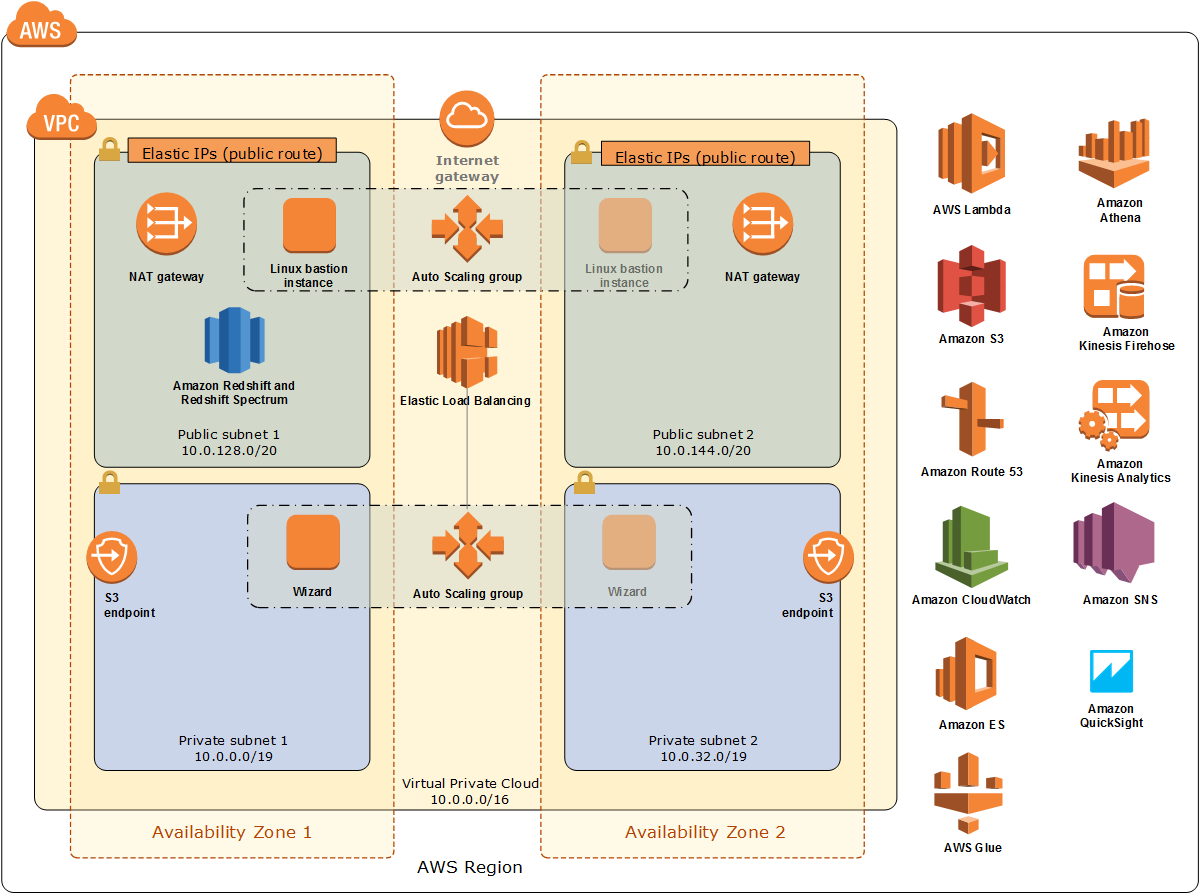
Herramientas de AWS para Data Lake
Ejemplo de arquitectura:
¿Qué es lo que debe permitir Data Lake?



